





China schockt die Welt mit zweitem DeepSeek-Sputnik-Moment
Red. – Dies ist ein Gastbeitrag. Leo Keller ist seit 2000 als Internet-Start-up-Gründer beruflich im Feld der Semantic Intelligence tätig (Sprach-KI). Microsoft kaufte die von ihm mitgegründete und aufgebaute Firma Netbreeze. Microsoft Dynamics integrierte sie als Social Listening Tool.
_____________________
Am 20. Januar, am Tag der Inauguration von Donald Trump, sorgte das neu vorgestellte chinesische KI-Modell DeepSeek für grosses Aufsehen. Es bot höhere Leistungen als die westliche Konkurrenz – bei massiv niedrigeren Kosten (3%) und deutlich tieferem Energieverbrauch (10%). Die Aktienkurse mehrerer Tech-Konzerne verloren daraufhin empfindlich an Wert. Nvidia verlor an einem Tag 589 Milliarden Dollar, der grösste Börsenverlust aller Zeiten. Und nun zeigt ein zweites chinesisches Unternehmen, dass es alle überflügeln kann – auch CLAUDE 3.5 von Anthropic, das aktuell beste amerikanische Modell. Nur bleiben diesmal die sichtbaren Reaktionen völlig aus. Mit Ausnahme von CNBC hat keines der grossen Mainstream-Medienhäuser in den USA oder Europa bisher berichtet. Die KI-Blogger sind aber alle rundum begeistert und veröffentlichen geradezu euphorische Berichte, nachdem sie das Kimi-K2-System ausgiebig getestet haben.
Eine Reaktion blieb aber nicht unbeobachtet: Sam Altman, Chef von OpenAI, verkündete am Tag nach der Kimi-K2- Veröffentlichung, dass ihre seit langem angekündigte Open-Version von ChatGPT ein weiteres Mal verschoben werden müsse:
Wir verzögern es. Wir benötigen Zeit, um zusätzliche Sicherheitstests durchzuführen und Hochrisikobereiche zu überprüfen. Wir wissen noch nicht genau, wie lange wir dafür brauchen werden.
Was Kimi K2 besser kann
In vier der acht standardisierten Tests liegt Kimi K2 vorne – besonders im automatischen Programmieren, der Mathematik und im Fachwissen. Claude Opus 4 schafft das in 3 Disziplinen, Chat CPT 4 von OpenAI in einer Disziplin. Das Modell ist darüber hinaus aber auch für «agentische Aufgaben» optimiert. Es kann also selber Tools wie Browser und Datenbanken nutzen, mehrstufige Aufgaben planen und durchführen und so als digitaler Agent dienen.
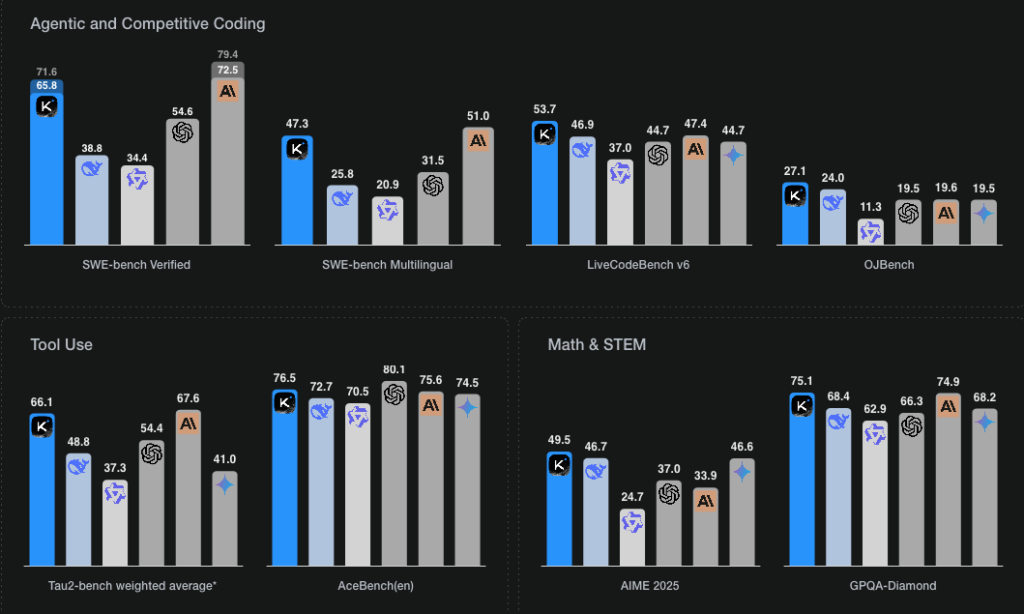
Warum es Kimi K2 und DeepSeek besser können
Schon DeepSeek überraschte die Welt total, dass es offenkundig möglich ist, gleich gute oder sogar bessere Ergebnisse zu erzielen, obwohl grundsätzlich die gleichen Daten aber eher schlechtere Chips (wegen GPU-Chip-Sanktionen) zur Verfügung stehen. Das Geheimnis liegt in der intelligenten Architektur.
Das Kimi-K2-Modell basiert auf einer «Mixture-of-Experts-Architektur» (MoE), d.h. bildlich gesprochen, MoE-Modelle trainieren nicht einen «Superexperten», sondern setzen – wie wir Menschen – auf viele Spezialisten, die gemeinsam das konkrete Problem lösen. Kimi K2 setzt sich aus 384 spezialisierten «Experten» zusammen. Sie können etwa auf Übersetzungen, mathematisches Denken oder kontextuelles Verständnis spezialisiert sein. Anstatt bei einer Anfrage den «Superexperten» – d.h. alle Experten – zu aktivieren, werden nur diejenigen aktiviert, die zur Lösung der konkreten Aufgabe beitragen können. Welche das sind, entscheidet ein «Router». Bei Kimi K2 und bei DeepSeek kommen jeweils acht spezialisierte sowie ein globaler Experte zusammen.
Die Konsequenzen scheinen enorm zu sein. «Kimi-Researcher stellt einen Paradigmenwechsel in der agentenbasierten KI dar», sagte Winston Ma, Lehrbeauftragter an der NYU School of Law. Er bezog sich auf die Fähigkeit der KI, mehrere Entscheidungen gleichzeitig selbstständig zu treffen, um eine komplexe Aufgabe zu bewältigen.
Anstatt lediglich flüssige Antworten zu generieren, demonstriert es autonomes Denken auf Expertenniveau – die Art komplexer kognitiver Arbeit, die bisher in LLMs [Red: Large Language Models] fehlte.
Warum Kimi K2 und DeepSeek billiger sind
Die beiden MoE-Modelle können sich in diesem hart umkämpften Markt sehr gut behaupten, denn sie offerieren ihre kostenpflichtigen Services zu sensationellen Preisen. Kimi K2 berechnet laut seiner Website nur 15 Cent pro Million Input-Token und 2,50 US-Dollar pro Million Output-Token. Token dienen der Datenmessung für die Verarbeitung von KI-Modellen.
Im Gegensatz dazu verlangt Claude Opus 4100 x mehr für Input – 15 US-Dollar pro Million Token – und 30 x mehr für Output – 75 US-Dollar pro Million Token. GPT 4.1 berechnet pro Million Token 2 US-Dollar für Input (13 x mehr) und 8 US-Dollar für Output (3 x mehr).

DeepSeek hatte seine Entwicklungskosten mit wenigen 100 Millionen Dollar angegeben – 3 Prozent der Kosten von OpenAI und ähnlichen Modellen. Für Kimi K2 hat Moonshot AI noch keine Entwicklungskosten publiziert.
Beide Firmen haben jeweils mit rund 100 bis 200 KI-Fachleuten in gut zwei Jahren ebenbürtige bis überlegene LMM-KI-Modelle realisiert. Die MoE-Architektur erlaubt es, mit deutlich billigeren GPU-Chips die gleichen Ergebnisse zu erzielen und den Energiebedarf drastisch zu senken.
Weckruf zur «Open-Source-Strategie» im Markt der hochentwickelten KI, die zur Superintelligenz werden kann
Die wichtigste Frage, die die wenigen Fachautoren und Tech-Blogger beschäftigt, heisst: Was braucht es noch, bis die amerikanischen Firmen (OpenAI, Anthropic, Google, Meta, xAI …) aufwachen? Nathan Lambert, ein anerkannter KI-Experte und Autor stellt pointiert fest:
Ein «DeepSeek-Moment» hat uns nicht zum Aufwachen gebracht, hoffentlich brauchen wir keinen dritten.
Seit der Präsentation von Kimi K2 am 11. Juli sollten wir wissen: DeepSeek war kein Zufall, kein Einzelfall und kein strategisches U-Boot in der KI-Geopolitik der chinesischen Regierung, sondern der Start der OpenSource-KI, die mächtiger und viel billiger ist als die proprietären Modelle der USA.
China nähert sich weiterhin der absoluten Grenze der Modellleistung. Der Westen fällt bei offenen Modellen noch weiter zurück. Aber auch die Sicherheits- und Risiko-Fragen stellen sich drängender und härter, denn es ist äusserst schwierig zu kontrollieren, wer hochmoderne Modelle trainieren kann, wenn sie so einfach sehr kostengünstig zu beschaffen und zu betreiben sind.
Die Kluft zwischen den führenden offenen Modellen westlicher Forschungslabore und ihren chinesischen Pendants wird immer grösser. Chinesische Unternehmen haben offensichtlich nützlichere Modelle mit freizügigeren Lizenzen veröffentlicht.
Angesichts der Tatsache, dass die Kimi K2 bisher keine nennenswerte Debatte weder in den Fachmedien noch in den Mainstream-Medien ausgelöst hat, – aber auch keine Reaktion an der Börse –, deutet darauf hin, dass es wohl noch weitere DeepSeek-Momente geben wird.
Themenbezogene Interessenbindung der Autorin/des Autors
Keine
_____________________
➔ Solche Artikel sind nur dank Ihren SPENDEN möglich. Spenden an unsere Stiftung können Sie bei den Steuern abziehen.
Mit Twint oder Bank-App auch gleich hier:
_____________________
Meinungen in Beiträgen auf Infosperber entsprechen jeweils den persönlichen Einschätzungen der Autorin oder des Autors.




Akademische Prüfstelle Kulturreferat der Deutschen Botschaft Peking: «Staatlich anerkannte Hochschulen Das chinesische Erziehungsministerium hat zurzeit (Stand 20.06.2025) 2.919 Hochschulen anerkannt. Zu diesen gehören 1.365 Universitäten inkl. der 211-Hochschulen. Diese Universitäten bieten als höchsten ersten Abschluss in vier- oder fünfjährigen sog. benke-Studiengängen einen Bachelor an…»
Interessante Hauptzeile: «China schockt die Welt mit zweitem DeepSeek-Sputnik-Moment» Die Frage ist wohl wer hat es möglich gemacht KI oder menschliche Intelligenz.
Auch Möglich, dass die chinesische Führung erkannte haben könnte, um die KI überwachen und beherrschen zu können braucht es eine menschliche-Intelligenz-Elite. Darum wohl, gibt es immer mehr Universitäten und Hochschulen im Reich der Mitte, weil man erkannte die menschliche Intelligenz darf nicht untergehen.
Gunther Kropp, Basel
Ob KI-Blogger begeistert sind, finde ich relativ uninteressant. Ebenso wenig aussagekräftig ist das Abschneiden in standardisierten Tests, denn die Modelle werden ja genau für diese Tests trainiert.
Spannend wäre doch, was diese Modelle bei neuen und unkonventionellen Fragestellungen abliefern. Geben sie ebenso ungerührt kreuzfalsche Antworten wie die bekannten US-Produkte? Sagen sie auch so Dinge, wie, man könne fliegen, wenn man nur ganz fest daran glaube? Können sie eine echte Arbeit erledigen, mit einer Fehlerquote, welche in der Praxis tolerierbar ist?
Dieser Aussage schliesse ich mich gerne an. Was zählt ist die Praxistauglichkeit.
Sehr guter Artikel. Schreibt hier Leo Keller von der SP Rüti? Kurzinfo zum Autor wäre jeweils hilfreich.
Danke für den Hinweis! Wir haben einige Informationen zum Gastautor beigefügt.
Hallo Herr Meier Buchs: nein es ist Leo Keller, Aarau aber auch SP Mitglied.